
前言
Materials你可以点击以下链接来获取
Agent Skills的资料:Waiting for api.github.com...
设想一个问题,帆帆用 Gemini 网页版来写自己的课程设计,如果他总是需要输入相似的 Prompt 指令来完成他的课程设计代码完善,那他是不是会花很多时间在修改 Prompt 或者编写自己的代码上?
例如:
- “你是一个资深的
Java工程师,现在你需要……” - “请遵守
MySQL中的下划线命名法,在Java代码中使用双驼峰命名法,而架构使用的是Spring Boot框架,不需要在…” - “现在你使用的是
Meavn项目,你需要在pom.xml中……”
在长期的输入相似文字的情况下,帆帆身心俱疲,他到底是在修改代码还是在给 AI 当一个无情的复读机?
而且,作为学生党,他还要默默承受住 Gemini 的额度问题,宝贵的 Token 就这样在一些小事上不断消耗,并且每个模型的记忆存储有限,过多的预设指令会占领AI的“短期记忆”的存储,聊到核心逻辑的时候却丢三落四,又得重新提示,又在消耗我们宝贵的Token。而这个问题我们通过 Agent Skills来解决。Agent Skills可以很有效地解决帆帆在 Gemini 网页版中不断复制粘贴到 IDE ,修改 prompt 提示词的问题。
什么是 Agent Skills?
核心概念
Agent Skills是一种扩展智能体能力的模块化指令集合。通过技能(Skill),Claude和其他 AI 智能体可以获得执行特定任务的新能力。
Skills是文件夹形式的指令集合,用于扩展智能体的能力,赋予其专门的知识来执行任务。
Skills 的核心特点是:
- 生态互通(Open Standard): 采用统一开放标准,打破平台壁垒,实现与任何主流智能体产品的无缝兼容。
- 高复用性(Build Once, Run Anywhere): 核心逻辑一次编写,即可跨平台多场景部署,极大降低开发与维护成本。
- 按需加载(Progressive Disclosure或渐进式披露): 优化长上下文管理,仅在语义匹配时加载完整指令,兼顾响应精度与系统性能。
1.1 使用 Skills 所需的工具
要运行和利用好 Agent Skills,智能体通常需要具备一套核心的底层工具集,这让它从一个“只能聊天”的对话框,变成一个“能干活”的数字员工。
Agent 需要以下基本工具集:
-
文件系统访问权限(Filesystem Access):能够读取、编写和修改本地文件,这是管理代码和文档的基础。
-
Bash 命令行工具:用于执行脚本、运行
Maven命令或启动测试环境。 -
网络访问(可选但推荐):通过
MCP(模型上下文协议) 获取外部实时数据。
1.2 Skills 的组合使用
Agent 可以将 Skills 与 MCP 和 子智能体 结合,创建强大的智能工作流:
Skills+MCP:Agent可以根据用户指令,调用Skills中的指令,同时利用MCP获取外部数据。Skills+Sub-Agent:Agent可以将Skills中的指令,作为子任务,传递给Sub-Agent执行。
具体表现在:
Skills + MCP(模型上下文协议)
解决了“数据在哪里”的问题,而 Skills 解决了“拿到数据后怎么做”的问题。
-
场景模拟:帆帆想给自己的
JianZi编辑器写一个自动化部署脚本。 -
如何联动:他可以使用
MCP连接到他的GitHub仓库获取最新的代码提交,然后依靠Skill(其中包含了他预设的打包发布流程)自动分析代码差异并执行Build任务。 -
价值:
MCP像是一条数据管道,将实时的外部信息源源不断地输送给具备特定“专业技能(Skill)”的Agent。
Skills + Sub-Agent
当一个任务过于庞大(例如重构整个课设项目)时,主智能体(Main Agent)可以召唤出具备独立上下文的子智能体(Sub-Agent)。
-
场景模拟:主智能体负责整体架构设计,它派出一个名为“
SQL专家”的子智能体。 -
如何联动:这个子智能体被赋予了帆帆编写的
SQL-Optimization-Skill。子智能体在一个独立、干净的上下文窗口中运行,只负责优化数据库 Schema,不会干扰主智能体对Java逻辑的思考。 -
价值:这种隔离性确保了任务的精确度,防止不同领域的指令互相干扰,也进一步保护了主
Agent的Token额度。
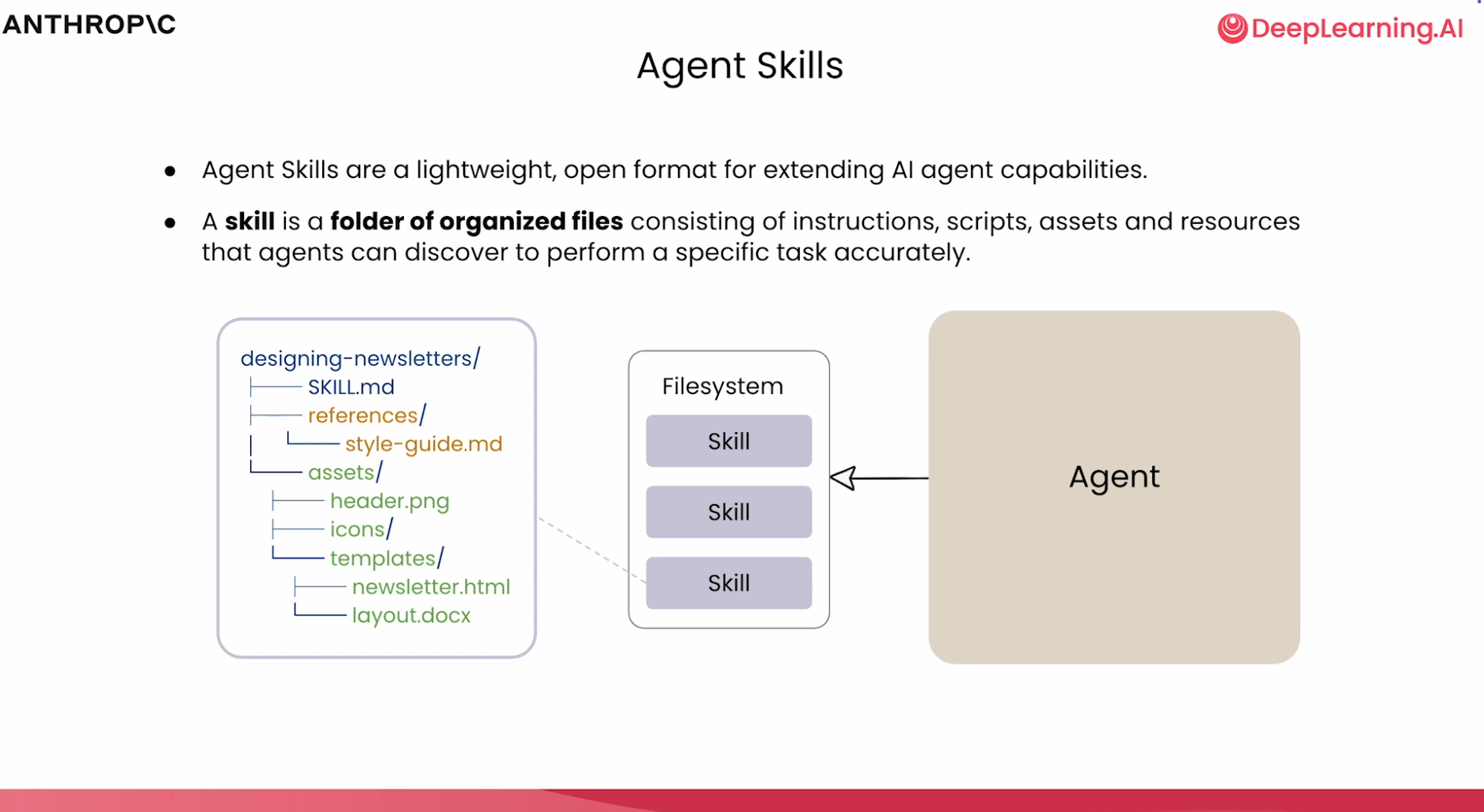
Skills 的三层构造
如果说 Agent 是大脑,那么 Skill 就是大脑中按需提取的“知识插件”。为了在保证专业性的同时不“撑爆” AI 的上下文窗口,Agent Skills 采用了一种极其精妙的三层构造:渐进式披露。
2.1 YAML 前置元数据(Metadata) ——总是在加载
这是 Skill 的“门牌号”,位于 SKILL.md 的最顶部。它决定了 AI 能否在成百上千个技能中准确地“认出”当前该用哪一个。
举个例子,我的博客也是用的 md 文档为基础,你看到的 Tags , Title 等等都是 YAML 前置元数据,通过他们来根据 md 文件渲染出来:
---title: 'Agent —— 从 Gemini 网页版再到 Gemini CLI标准化流程'description: '这是一段描述'tags: [Agent]category: Intelligence---- title:代表着这个文章在博客中渲染出来的标题
- description:在主页点进来前看到的文字描述
- tags:为文章的标签,我们这里的标签是Agent,也可以在其中添加别的标签
- category:分类,决定了这篇文章在哪个目录下展示。
对网页而言,是如何把这个 md 根据 Metadata 来渲染出来对应的页面
而对于 Skills而言,其参数最主要的有两个,分别是 name 和 description
---name: marketing-campaign-analyzerdescription: 用于分析营销渠道数据。当提到转化漏斗、点击效率或预算重新分配时触发。----
name(技能名称):这是技能的唯一标识符。在 UI 界面或 CLI 工具中,当技能被触发时,你会看到这个名字闪烁,提醒你:“专业外援已介入”。
-
description(功能描述):这是整套机制的“灵魂”。 AI 会持续监听对话上下文,并将其与所有已加载技能的
description进行语义匹配。
2.2 Markdown 指令正文 —— 触发时加载
一旦描述被命中,AI 就会把 SKILL.md 中的详细指令装载进内存。这部分就是帆帆原本需要不断复制粘贴的 Prompt:
- 输入规范(Input):定义代码的输入格式、Maven 的依赖环境。
- 逻辑准则:
- 命名法:
MySQL下划线 vsJava双驼峰。 - 架构约束:
Spring Boot项目的目录结构。
- 命名法:
- 输出要求:定义代码注释规范、错误处理逻辑或生成报表的样式。
加载逻辑:按需触发。 只有当帆帆真的开始聊相关话题时,这些重头戏才会登场,有效防止了无意义的 Token 消耗。
2.3 外部资源与脚本(Resources)—— 必要时加载
这是 Skill 构造的最外层。在 SKILL.md 指令中,我们可以引用外部的“重型武器”:
- References:存放放在
references/文件夹里的厚重文档(如《Java 开发手册》)。 - Scripts:存放可执行的 Bash 或 Python 脚本(如自动运行
mvn clean的工具)。
加载逻辑:绝对的“懒加载”。 只有指令执行到“请查阅文档”或“请运行脚本”时,AI 才会去翻阅这些资源。
Excel Skills 实践
3.1 目录结构示例
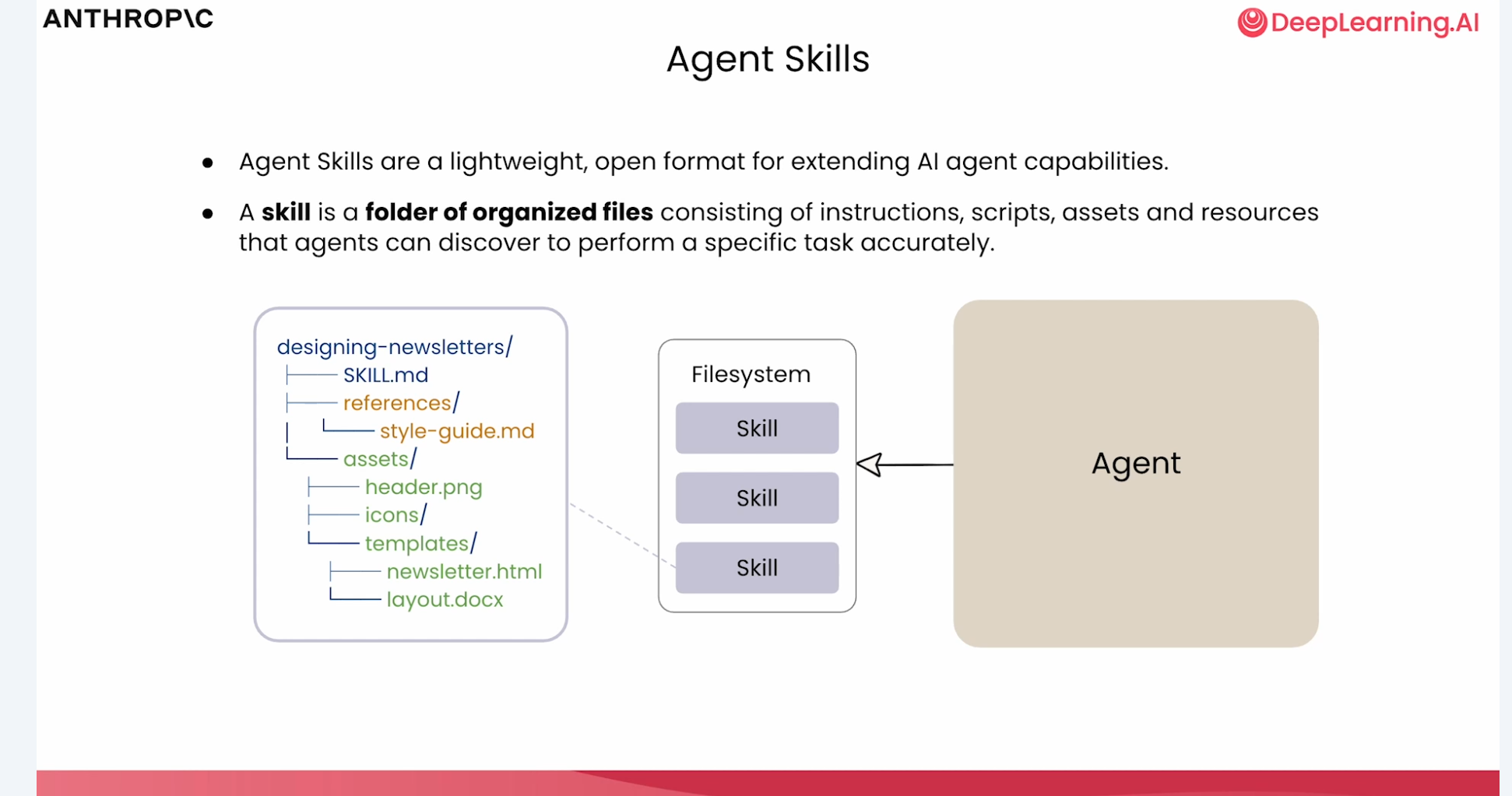
以 materials 提供的资料分析,Skill 目录结构如下:
analyzing-marketing-campaign/├── SKILL.md└── references/ └── budget_relocation_rules.mdSKILL.md:主说明文档,描述 Skill 用途、输入输出、核心流程references/:存放参考规则、模板、辅助文档等
3.2 SKILL.md 内容与 YAML元数据
SKILL.md 通常包含 YAML Frontmatter(元数据区块),以及详细的任务描述、输入输出格式、核心指标和操作流程。例如:
---name: analyzing-marketing-campaigndescription: 分析多渠道数字营销数据,计算转化漏斗、效率指标,并给出预算调整建议。inputs: - file: Excel/CSV,包含Date, Campaign_Name, Channel, Impressions, Clicks, Conversions, Spend, Revenue, Orders等字段outputs: - Markdown/Excel表格,含各项指标与建议---
## 任务流程1.读取Excel/CSV数据。2.计算各渠道CTR(点击率)、CVR(转化率)。3.计算ROAS(广告回报率)、CPA(获客成本)、净利润等效率指标。4.输出对比表格,生成分析解读与预算建议。
## 公式示例-CTR% = Clicks / Impressions * 100-CVR% = Conversions / Clicks * 100-ROAS = Revenue / Spend-CPA = Spend / Conversions-Net Profit = Revenue - (Spend + 其它成本)3.3 实现与案例
3.3.1 常见 Excel 自动化任务
- 数据汇总与统计(如销售总额、最大单笔交易)
- 条件格式化(如根据状态标记行颜色)
- 多表合并(如客户与订单表按 ID 合并)
- 批量文件生成(如根据模板自动生成邀请函、产品文档)
- 数据过滤、排序与导出
3.3.2 Excel Skill 实现的技术路线
工具选择
- pandas:适合批量数据处理、分析、导出
- openpyxl:适合复杂格式、公式、Excel 特性操作
工作流程
- 选择工具:根据需求选择 pandas 或 openpyxl
- 创建/加载文件:新建或读取工作簿
- 数据处理:增删改查、公式、格式化
- 保存文件:写回 Excel
- 公式重算:如涉及公式,需用 recalc.py 脚本进行重算(openpyxl 仅写入公式字符串,不计算结果)
- 错误校验与修复:Skill 应返回 JSON 报告所有错误类型和位置,便于二次修正
3.3.3 Skill 文件夹完整结构
excel-skill/├── SKILL.md├── scripts/│ ├── process_data.py│ ├── recalc.py├── references/│ ├── example_input.xlsx│ ├── output_template.xlsx│ └── rules.md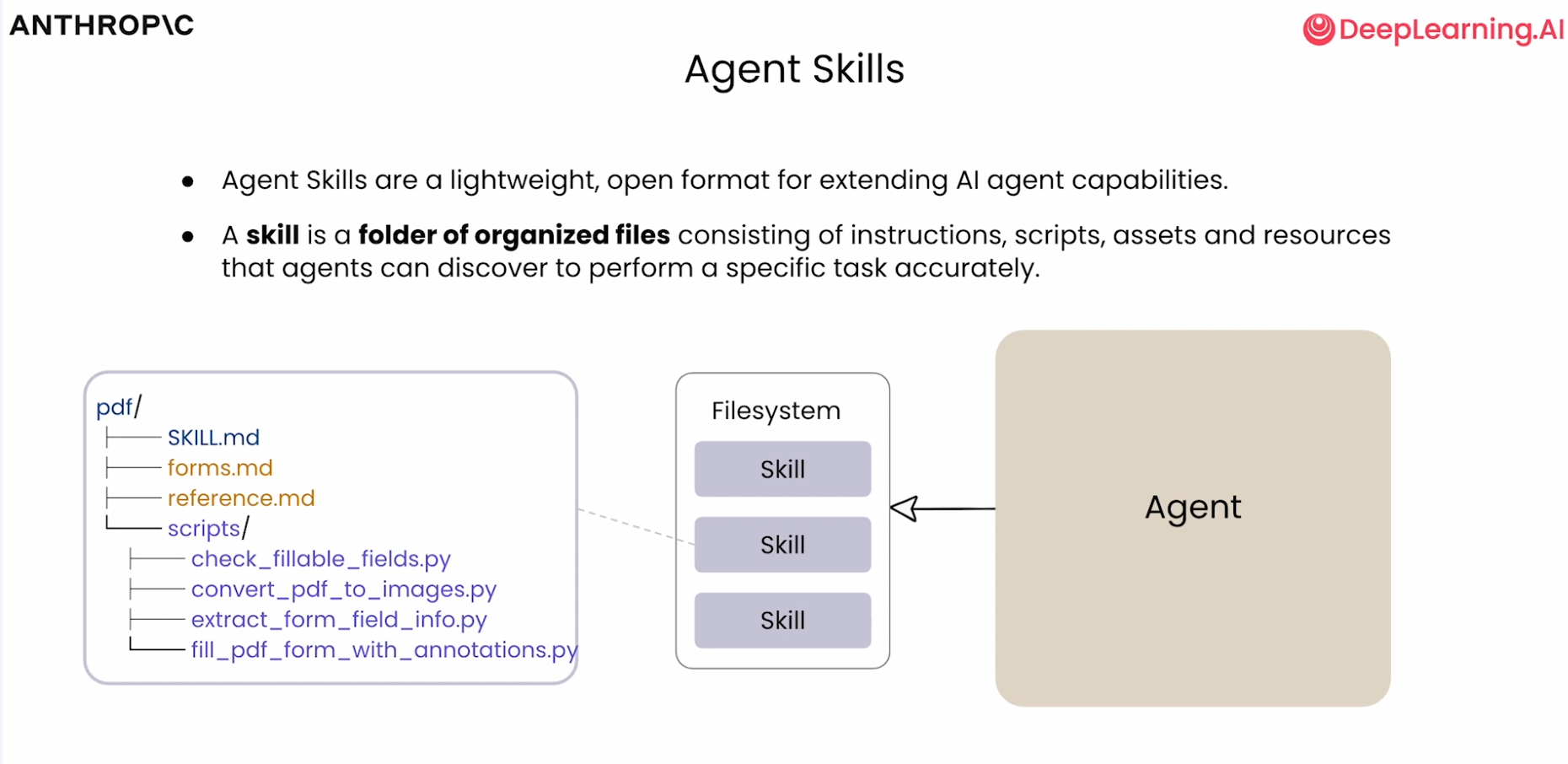
scripts/:存放数据处理、公式重算等 Python 脚本references:输入样例、输出模板、规则文档SKILL.md:说明 Skill 用途、输入输出、流程与注意事项
3.3.4 实践建议与最佳实践
- 明确
Skill的输入输出标准,示例文件放在references目录 - 所有脚本应有异常处理与错误报告能力,便于
Agent自动修复 - 复杂逻辑建议分模块实现,主流程在
SKILL.md中清晰描述 Excel公式相关操作建议分离脚本处理,避免直接在openpyxl中计算- 尽量输出中间结果与最终数据,便于人工或
Agent二次校验
Agent 与瑞士军刀
我觉得 CS61B 里有一个例子特别好,可以用来举一下,对于类继承,我们一般不会要求父类太复杂,这样子类也就很简单,不会很臃肿。

同样的,我觉得 Agent 也要像瑞士军刀一样,一把瑞士军刀不需要承载太多的功能,我们只需要一些所需要的功能即可,因为在钥匙串里找到我们要找的钥匙很麻烦,但是在一堆由单把钥匙构成的挂扣中,我们可以精准地找到某某宿舍的钥匙。
所以我们使用 Agent Skills的时候,每把钥匙(Skill.md)其指令正文就必须做到精准,一旦 Metadata 匹配成功,AI 就会加载这一部分的详细指令。
# Java 课设助手指令集
## 1. 输入协议 (Input Handling)- **文件识别**:当检测到 `pom.xml` 时,优先审查 `<dependencyManagement>` 和 `<properties>` 标签以确保版本一致性。- **上下文感知**:读取 `Controller` 或 `Service` 类时,自动关联对应的 `Mapper/Repository` 接口。
## 2. 核心逻辑 (Core Logic)- **命名契约**: - **Java 层**:严格执行 $\text{CamelCase}$ (大/小驼峰命名法)。 - **数据库层**:严格执行 $\text{snake\_case}$ (下划线命名法)。- **映射规则**:在处理 MyBatis 映射或 JPA 实体类时,必须确保 Java 字段名(如 `userId`)与数据库列名(如 `user_id`)的自动转换逻辑已配置。- **架构约束**:基于 Spring Boot 标准三层架构,严禁在 `Controller` 层直接编写业务逻辑。
## 3. 异常处理 (Exception Handling)- **依赖冲突**:若发现 Maven 存在版本冲突,禁止仅输出 Error,必须提供 `mvn dependency:tree` 的分析建议。- **规范偏离**:若用户输入的代码违反了命名契约,需先给出修改建议,待用户确认后再进行后续逻辑编写。-
输入协议(Input Handing):
明确告诉 AI 如何“读取”你的钥匙。例如:“当看到
pom.xml时,首先检查dependencyManagement标签”。 -
核心逻辑(Core Logic):
-
Java 层:强制执行 (驼峰法)。
-
数据库层:强制执行 (下划线法)。
-
映射机制:明确要求在
MyBatis或JPA映射中,如何处理这两者的转换。
-
-
异常处理(Exception Handling):
“如果发现 Maven 依赖冲突,不要直接报错,请给出一份依赖树分析建议”
又或者说,一个集大成者的 Agent 是很蠢的,假设 Agent 要谈恋爱,他总不可能会要负责数学模块,物理模块的 Skill 去负责追喜欢的人吧?他肯定是会用专门负责聊天模块,外貌模块等等一系列利于谈恋爱这个目的的 Skills,在谈恋爱的时候就大胆用恋爱模块的 Skills ,在写数学题的时候就大胆用 物理和数学模块的Skills。所以说,术业有专攻,我们肯定要灵活运用,同时也可以省下一笔不菲的开销。
结语
一个“集大成者”的 Agent 往往是平庸的。真正的标准化流程,是根据当前目的灵活切换特定的 Skills。
通过 Agent Skills,我们不仅解决了“复读机”式的体力劳动,更是在有限的上下文空间内,通过模块化和按需加载,让 AI 真正进化为各领域的垂直专家。